
 Vladimir Curiel
Vladimir Curiel
Categorías
Etiquetas
ActiveMQ Android Astro Bootstrap Clerk Convex DataFaker Docker Firebase Flutter Go GraphQL HAProxy HTML JasperReports Java Javalin JMS JS Juyper Notebook Mailjet Microservices MongoDB Mux NestJS NextAuth NextJS NLP NLTK Numpy Pandas PayPal Postgres PostgreSQL Prisma Python Re React Redis Resend RSS Scikit-learn Scikit-Learn SCSS Spacy SpringBoot Streamlit Tableau TailwindCSS Vaadin WebGPU WordPress YouTube API ZenStack
108 palabras
1 minutos
Sistema de recuperación de información
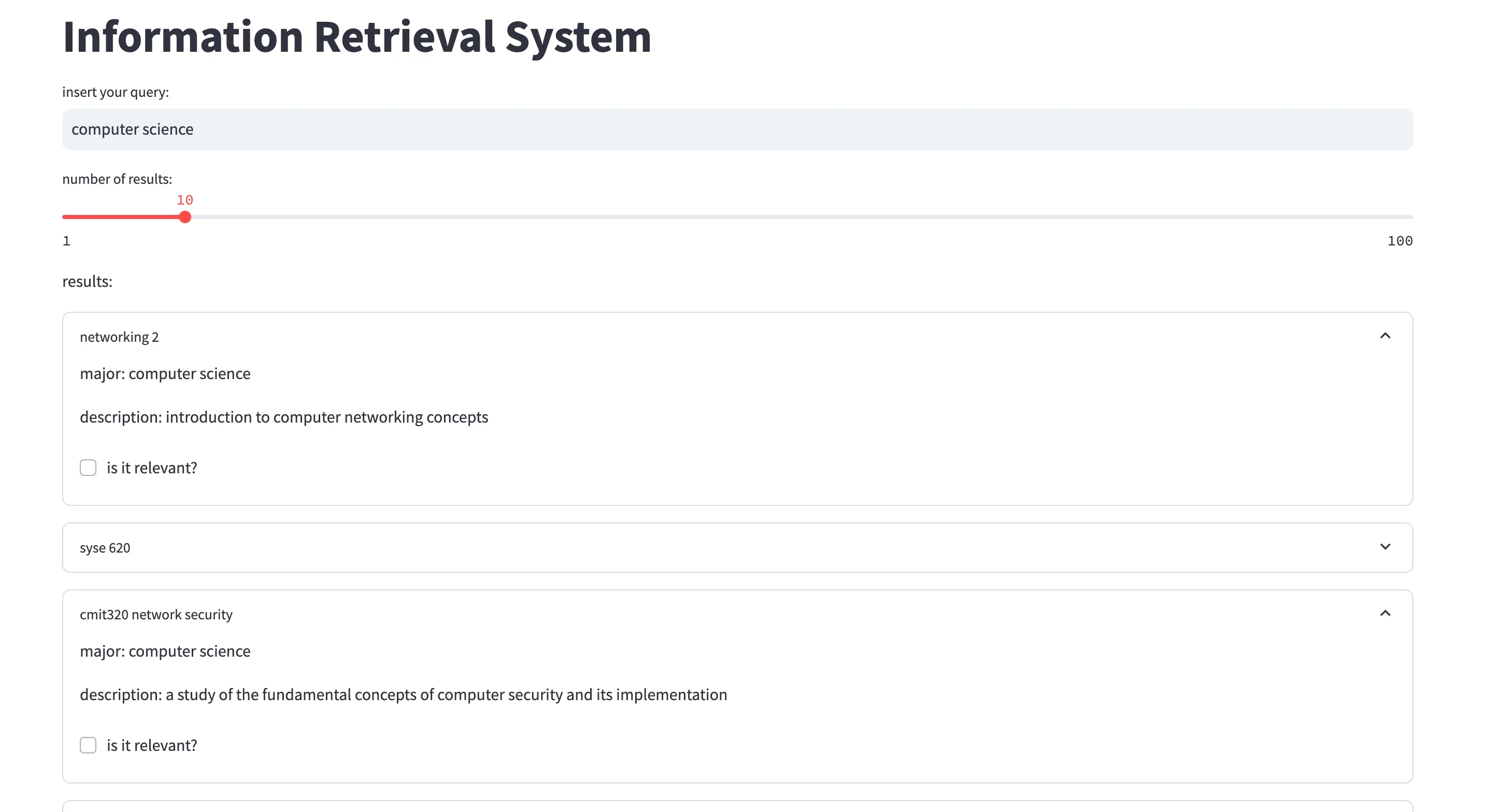
Sistema de recuperación de información
Este proyecto es un sistema de recuperación de información utilizando procesamiento de lenguaje natural. El sistema permite buscar documentos en una colección de documentos, utilizando un modelo de espacio vectorial y un modelo de lenguaje.
El sistema cuenta con una interfaz gráfica creada con Streamlit, la cual permite al usuario ingresar una consulta y obtener los documentos más relevantes a la consulta. Para ello, el sistema utiliza la librería NLTK, Spacy, Scikit-learn, Pandas y Numpy.
El dataset utilizado para este proyecto es Country Tuition Assistance Program, el cual contiene información sobre los programas de asistencia de matrícula en los condados de los Estados Unidos.
Repositorio de GitHub
Waiting for api.github.com...
Sistema de recuperación de información
https://vladimircuriel.com/posts/information-retrival-system/